The trendLevel() function provides a way of rapidly showing a large amount
of data in a condensed form. In one plot, the variation in the concentration
of one pollutant can to shown as a function of between two and four
categorical properties. The default arguments plot hour of day on the x-axis
and month of year on the y-axis. However, x, y and type and summarising
statistics can all be modified to provide a range of other similar plots, all
being passed to cutData() for discretisation. The average wind speed and
direction in each bin can also be plotted using the windflow argument.
Usage
trendLevel(
mydata,
pollutant = "nox",
x = "month",
y = "hour",
type = "default",
rotate.axis = c(90, 0),
n.levels = c(10, 10, 4),
windflow = NULL,
limits = NULL,
breaks = NULL,
trans = FALSE,
min.bin = 1,
cols = "default",
theme = "default",
auto.text = TRUE,
key.title = paste("use.stat.name", pollutant, sep = " "),
key.position = "right",
statistic = c("mean", "max", "min", "median", "frequency", "sum", "sd", "percentile"),
percentile = 95,
stat.args = NULL,
stat.safe.mode = TRUE,
drop.unused.types = TRUE,
col.na = "white",
plot = TRUE,
key = NULL,
...
)Arguments
- mydata
The openair data frame to use to generate the
trendLevel()plot.- pollutant
The name of the data series in
mydatato sample to produce thetrendLevel()plot.- x, y, type
The name of the data series to use as the
trendLevel()x-axis, y-axis or conditioning variable, passed tocutData(). These are used before applyingstatistic.trendLevel()does not allow duplication inx,yandtypeoptions.- rotate.axis
The rotation to be applied to
trendLevelxandyaxes. The default,c(90, 0), rotates the x axis by 90 degrees but does not rotate the y axis. If only one value is supplied, this is applied to both axes; if more than two values are supplied, only the first two are used.- n.levels
The number of levels to split
x,yandtypedata into if numeric. The default,c(10, 10, 4), cuts numericxandydata into ten levels and numerictypedata into four levels. This option is ignored for date conditioning and factors. If less than three values are supplied, three values are determined by recursion; if more than three values are supplied, only the first three are used.- windflow
If
TRUE, the vector-averaged wind speed and direction will be plotted using arrows. Alternatively, can be a list of arguments to control the appearance of the arrows (colour, linewidth, alpha value, etc.). SeewindflowOpts()for details.- limits
The limits of the colour scale, in the form
c(lower, upper). For example,limits = c(0, 100)will set the colour scale to be between0and100. Values greater than100will be coloured as if they were100, and those lower than0will be coloured as if they were0.limitscan be wider than the range of the data, which can be useful for ensuring multiple plots share the same colour scale.- breaks
breaksbins a continuous axis into discrete bins. It can either take a single number (e.g.,breaks = 5) to split the scale into quantiles, a vector of numbers (e.g.,breaks = c(0, 50, 100, 200, 500) to define specific break-points, or a named list. SeebreakOpts()for more details.- trans
Should a transformation be applied to the colour scale? If the distribution of data is skewed, the default scale may be dominated by a few high values, so a log or square-root transform may mean the whole colour scale is better presented on the plot. Can be:
FALSE, which performs no transform.TRUE, which uses an appropriate transform for the plot type (usually"log10").A
scales'transform' object (e.g.,scales::transform_log10()).A character string corresponding to a
scalestransform function. Useful options include"sqrt","log10","log2","log1p","pseudo_log"and"reverse".
- min.bin
The minimum number of records required in a bin to show a value. Bins with fewer than
min.binrecords are set toNA. The default is 1, i.e., all bins with no records are set toNA. Settingmin.binto a value greater than 1 can be useful to exclude bins with very few records that might produce unreliable statistic values.- cols
Colours to use for plotting. Can be a pre-set palette (e.g.,
"turbo","viridis","tol","Dark2", etc.) or a user-defined vector of R colours (e.g.,c("yellow", "green", "blue", "black")- seecolours()for a full list) or hex-codes (e.g.,c("#30123B", "#9CF649", "#7A0403")). Alternatively, can be a list of arguments to control the colour palette more closely (e.g.,palette,direction,alpha, etc.). SeeopenColours()andcolourOpts()for more details.- theme
A string representing an overall plot theme, defaulting to
"default". This option makes sweeping changes to non-data plot features such as fonts, colours, line widths, and so on, and may also change default arguments likecolsif not set by the user. Can also take aggplot2::theme()object, which will be used to modify the"default"theme. Pre-set options include:"default", a lattice-inspired theme resembling the traditionalopenairlook, with structured panels and visible gridlines."dark", a dark-background variant of the default theme, designed for presentations and low-light viewing, using high-contrast text and colour palettes optimised for visibility against dark panels."modern", a minimalist, contemporary theme inspired by tools such as Plotly and Observable Plot, with reduced visual clutter, horizontal emphasis in gridlines, a clean legend style, and typography suited to dashboards and reports."soft", a low-contrast, 'editorial' theme with warm background tones, subtle gridlines, and gently desaturated colours, designed for reports and publication-style figures, particularly where a calmer appearance improves readability."print", a strictly greyscale theme optimised for black-and-white reproduction, with stronger structural elements such as clearer gridlines and axis definitions to ensure good contrast and readability in printed or photocopied outputs.
Please note that if a global theme is set with
ggplot2::theme_set()to anything other than the defaultggplot2::theme_grey(), the selected openair theme will not be fully applied; instead, only minimal adjustments (such as legend positioning) will be made.- auto.text
Either
TRUE(default) orFALSE. IfTRUEtitles and axis labels will automatically try and format pollutant names and units properly, e.g., by subscripting the "2" in "NO2". Passed toquickText().- key.title
Used to set the title of the legend. The legend title is passed to
quickText()ifauto.text = TRUE.- key.position
Location where the legend is to be placed. Allowed arguments include
"top","right","bottom","left"and"none", the last of which removes the legend entirely.- statistic
The statistic to apply when aggregating the data; default is the mean. Can be one of
"mean","max","min","median","frequency","sum","sd","percentile". Note that"sd"is the standard deviation,"frequency"is the number (frequency) of valid records in the period and"data.cap"is the percentage data capture."percentile"is the percentile level (%) between 0-100, which can be set using the"percentile"option. Functions can also be sent directly viastatistic; see 'Details' for more information.- percentile
The percentile level used when
statistic = "percentile". The default is 95%.- stat.args
Additional options to be used with
statisticif this is a function. The extra options should be supplied as a list of named parameters; see 'Details' for more information.- stat.safe.mode
An addition protection applied when using functions directly with
statisticthat most users can ignore. This option returnsNAinstead of runningstatisticon binned sub samples that are empty. Many common functions terminate with an error message when applied to an empty dataset. So, this option provides a mechanism to work with such functions. For a very few cases, e.g., for a function that counted missing entries, it might need to be set toFALSE; see 'Details' for more information.- drop.unused.types
Hide unused/empty
typeconditioning cases. Some conditioning options may generate empty cases for some data sets, e.g. a hour of the day when no measurements were taken. Emptyxandycases generate 'holes' in individual plots. However, emptytypecases would produce blank panels if plotted. Therefore, the default,TRUE, excludes these empty panels from the plot. The alternativeFALSEplots alltypepanels.- col.na
Colour to be used to show missing data.
- plot
When
openairplots are created they are automatically printed to the active graphics device.plot = FALSEdeactivates this behaviour. This may be useful when the plot data is of more interest, or the plot is required to appear later (e.g., later in a Quarto document, or to be saved to a file).- key
Deprecated; please use
key.position. IfFALSE, setskey.positionto"none".- ...
Addition options are passed on to
cutData()fortypehandling. Some additional arguments are also available, varying somewhat in different plotting functions:title,subtitle,caption,tag,xlabandylabcontrol the plot title, subtitle, caption, tag, x-axis label and y-axis label, passed toggplot2::labs()viaquickText()ifauto.text = TRUE.xlim,ylimandlimitscontrol the limits of the x-axis, y-axis and colorbar scales.ncolandnrowset the number of columns and rows in a faceted plot.scalescan be"fixed","free_x","free_y"or"free"to control whether axes are shared across facets when usingtype. Also supported are the legacyx.relationandy.relation, which can be either"same"or"free"and get remapped toscalesautomatically.Similarly,
space,axes,axis.labels,switchandstrip.positioncan be used to customise the appearance of faceted plots. Seeggplot2::facet_wrap()andggplot2::facet_grid()for the arguments these take.fontsizeoverrides the overall font size of the plot by setting thetextargument ofggplot2::theme(). It may also be applied proportionately to anyopenairannotations (e.g., N/E/S/W labels on polar coordinate plots).Various graphical parameters are also supported:
linewidth,linetype,shape,size,border, andalpha. Not all parameters apply to all plots. These can take a single value, or a vector of multiple values - e.g.,shape = c(1, 2)- which will be recycled to the length of values needed.lineend,linejoinandlinemitretweak the appearance of line plots; seeggplot2::geom_line()for more information.In polar coordinate plots,
annotate = FALSEwill remove the N/E/S/W labels and any other annotations.
Value
an openair object.
Details
trendLevel() allows the use of third party summarising functions via the
statistic option. Any additional function arguments not included within a
function called using statistic should be supplied as a list of named
parameters and sent using stat.args. For example, the encoded option
statistic = "mean" is equivalent to statistic = mean, stat.args = list(na.rm = TRUE) or the R command mean(x, na.rm = TRUE). Many R
functions and user's own code could be applied in a similar fashion, subject
to the following restrictions: the first argument sent to the function must
be the data series to be analysed; the name 'x' cannot be used for any of the
extra options supplied in stat.args; and the function should return the
required answer as a numeric or NA. Note: If the supplied function returns
more than one answer, currently only the first of these is retained and used
by trendLevel(). All other returned information will be ignored without
warning. If the function terminates with an error when it is sent an empty
data series, the option stat.safe.mode should not be set to FALSE or
trendLevel() may fail. Note: The stat.safe.mode = TRUE option returns an
NA without warning for empty data series.
Examples
# basic use
# default statistic = "mean"
trendLevel(mydata, pollutant = "nox")
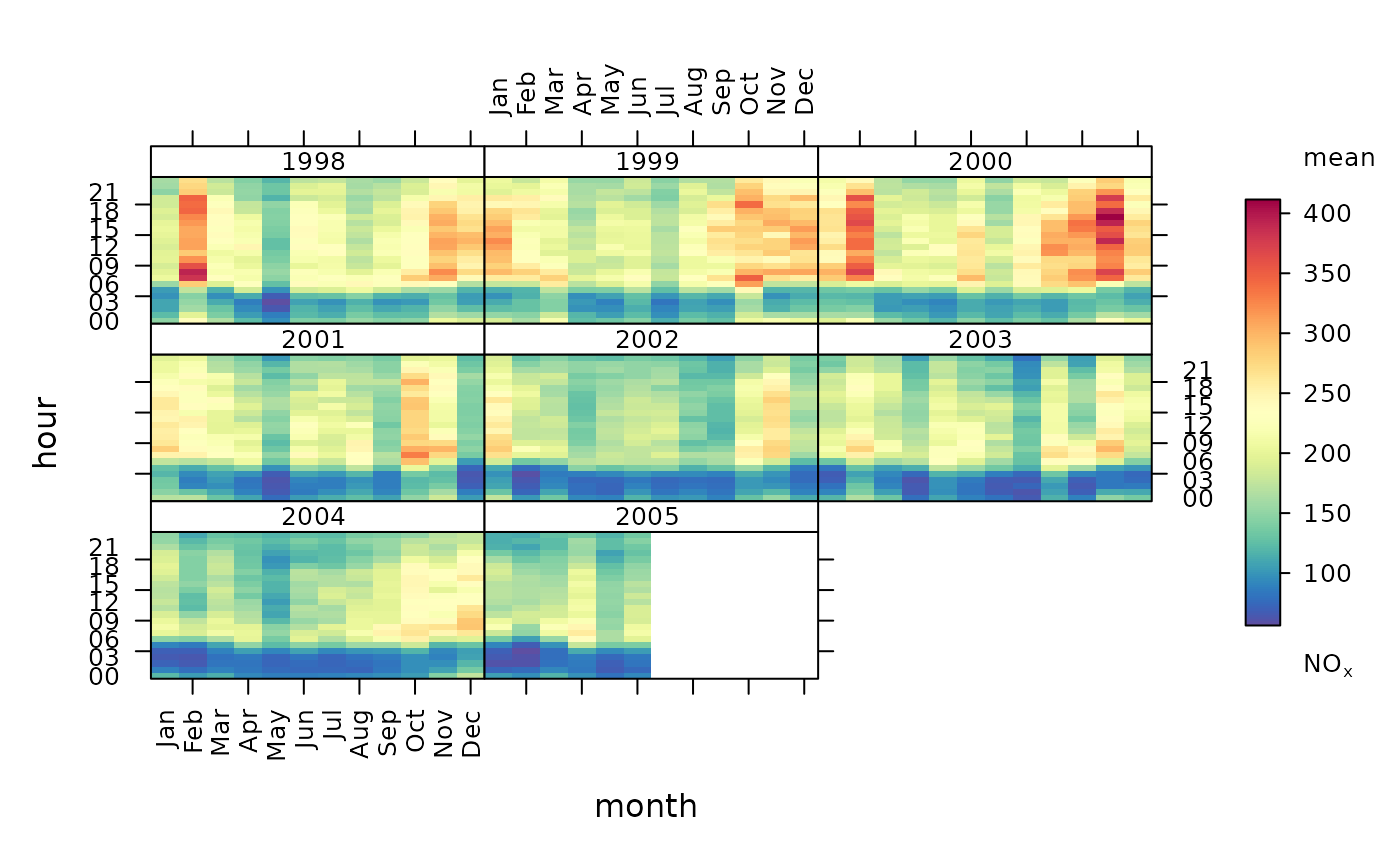 # applying same as 'own' statistic
my.mean <- function(x) mean(x, na.rm = TRUE)
trendLevel(mydata, pollutant = "nox", statistic = my.mean)
# applying same as 'own' statistic
my.mean <- function(x) mean(x, na.rm = TRUE)
trendLevel(mydata, pollutant = "nox", statistic = my.mean)
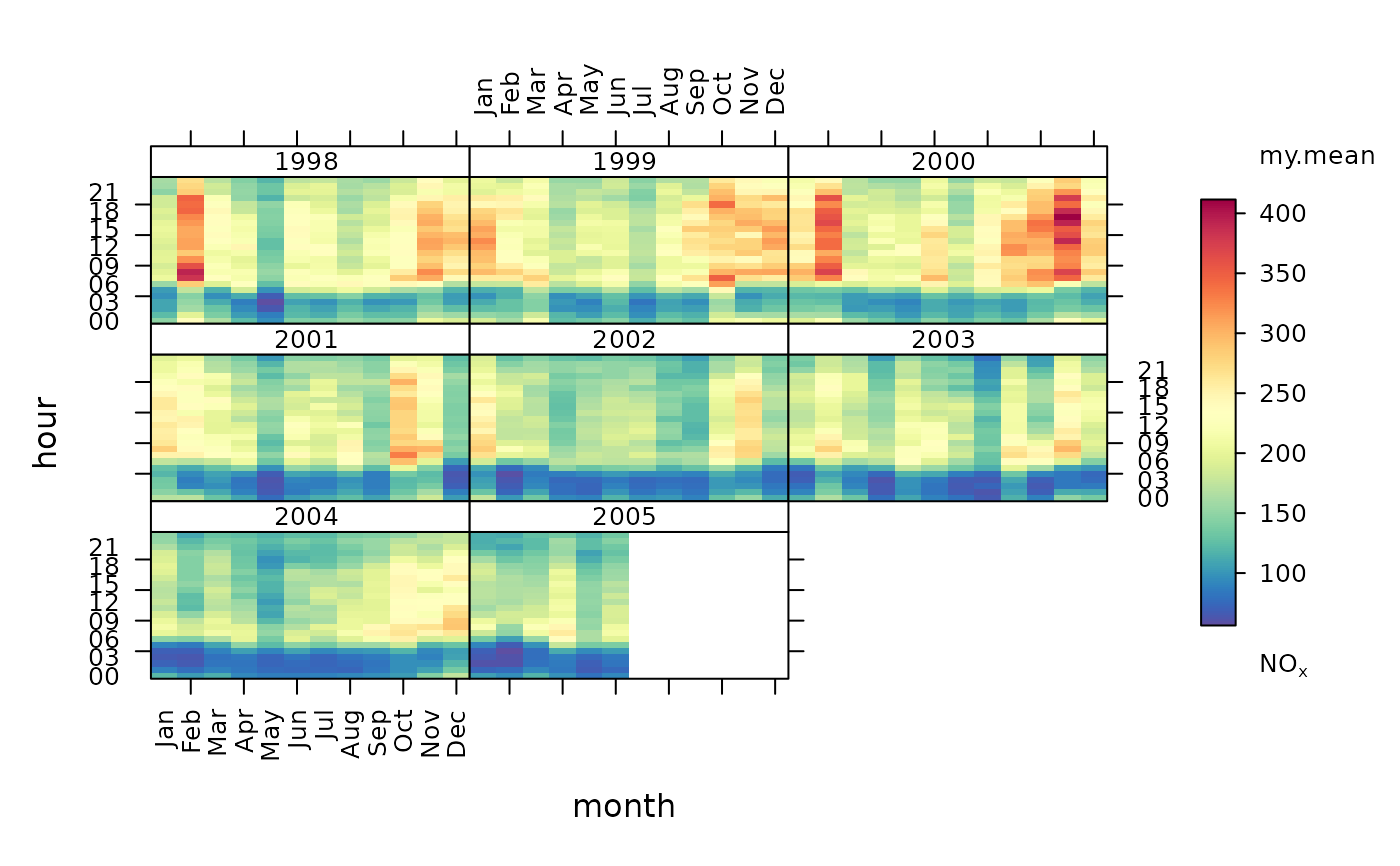 # alternative for 'third party' statistic
# trendLevel(mydata, pollutant = "nox", statistic = mean,
# stat.args = list(na.rm = TRUE))
if (FALSE) { # \dontrun{
# example with categorical scale
trendLevel(mydata,
pollutant = "no2",
border = "white", statistic = "max",
breaks = c(0, 50, 100, 500),
labels = c("low", "medium", "high"),
cols = c("forestgreen", "yellow", "red")
)
} # }
# alternative for 'third party' statistic
# trendLevel(mydata, pollutant = "nox", statistic = mean,
# stat.args = list(na.rm = TRUE))
if (FALSE) { # \dontrun{
# example with categorical scale
trendLevel(mydata,
pollutant = "no2",
border = "white", statistic = "max",
breaks = c(0, 50, 100, 500),
labels = c("low", "medium", "high"),
cols = c("forestgreen", "yellow", "red")
)
} # }